Wer Software dokumentiert, kennt das Grundproblem: Screenshots altern schnell. Nach größeren UI-Änderungen passen sie nicht mehr sauber zum Produkt, und das Benutzerhandbuch wird leicht zu einem Thema, das immer wieder auf später verschoben wird.
Bei AGYNAMIX Invoicer wollten wir diesen Teil der Dokumentation verlässlicher machen. Es ging nicht nur darum, ein paar schöne Bilder zu erzeugen. Wir wollten einen Weg finden, ein komplettes Benutzerhandbuch systematisch aus dem Produkt heraus zu bebildern.
Rückblickend wurde der entscheidende Fortschritt erst möglich, als wir den ersten Ansatz wieder losgelassen haben.
Warum der erste Ansatz nicht getragen hat
Am Anfang dachten wir prozessorientiert. Die Idee war, die Anwendung in einem stabilen Zustand zu starten, die nötigen Screens abzunavigieren und dann das komplette Fenster zu erfassen, möglichst mitsamt echter Fensterumgebung.
Auf dem Papier wirkte das plausibel:
- das Handbuch sollte reale Anwendungssituationen zeigen
- die Screenshots sollten wie “echte” App-Fenster aussehen
- die Umgebung sollte einmal definiert und dann reproduzierbar eingefroren werden
In der Praxis lief dieser Ansatz aber in genau die Probleme, die Desktop-Software regelmäßig unangenehm machen:
- native Menüleisten sind keine stabile Testoberfläche
- Dateidialoge und externe Viewer gehören dem Betriebssystem, nicht unserer Compose-Oberfläche
- Fenster-Chrome, Skalierung und Timing erzeugen visuelles Rauschen statt verlässlicher Reproduzierbarkeit
- ein prozessorientierter Ablauf beantwortet noch nicht die wichtigere Frage, welche Screenshots überhaupt existieren und wem sie fachlich gehören
Der eigentliche Fehler lag also nicht zuerst in der Technik, sondern im Modell. Wir hatten den Capture-Prozess beschrieben, bevor wir sauber erfasst hatten, welche Dokumentationsassets überhaupt entstehen sollten.
Ein Architekturpunkt ist dabei wichtig, damit der Rest dieses Artikels klarer wird: AGYNAMIX Invoicer ist keine Webanwendung, sondern eine native Desktop-Anwendung auf Basis von Kotlin und JetBrains Compose for Desktop. Die Pipeline fotografiert also keinen Browser-DOM, sondern gezielt kontrollierte Compose-Szenen einer Desktop-App, deren Screens, Dialoge und Zustände über ein dediziertes Test-Harness angesteuert werden.
Der eigentliche Wechsel: vom Fenster zum Screenshot-Katalog
Der Durchbruch kam, als wir die Perspektive umgedreht haben. Statt vom Capture-Mechanismus aus zu denken, sind wir vom Benutzerhandbuch ausgegangen.
Die neue Leitfrage lautete nicht mehr: “Wie fotografieren wir die App?”, sondern: “Welche konkreten Screenshot-Artefakte braucht das Handbuch überhaupt?”
Daraus entstand ein kataloggetriebener Ansatz:
- Alle Screenshot-Platzhalter aus dem deutschen Handbuch werden vollständig inventarisiert.
- Jeder Eintrag bekommt eine stabile ID, einen Zielpfad, eine Klassifikation und eine inhaltliche Beschreibung.
- Nur katalogisierte Assets dürfen automatisiert erzeugt werden.
- Screenshot-Tests erzeugen keine beliebigen Bilder, sondern genau die Assets, die im Katalog deklariert sind.
Diese Verschiebung klingt kleiner, als sie in der Praxis war. Auf einmal war nicht mehr der Test der Primäranker, sondern das Dokumentationsinventar. Der Test wurde zum reproduzierbaren Produktionsschritt für ein vorher definiertes Asset.
Was daraus konkret geworden ist
Aus dem Benutzerhandbuch wurde zunächst ein maschinenlesbarer Katalog. Der aktuelle Stand umfasst heute:
- 348 katalogisierte Manual-Einträge insgesamt
- 343 automatisierbare Screenshots
- 5 generierte Illustrationen als eigener, separater Workflow
- 336 Screenshot-Tests im dedizierten Screenshot-Paket
Das war für uns der Punkt, an dem das Vorhaben von einer interessanten Idee zu einem beherrschbaren System wurde.
Denn ab da ließ sich die Arbeit in wohldefinierte Einheiten schneiden:
- Dashboard-Screenshots
- Dokumenten-Screenshots
- Kunden-, Artikel- und Textbaustein-Screenshots
- Settings-, Menubar- und GoBD-Szenen
- Sonderfälle mit Mocking oder Helper-Scenes
Gerade bei größeren Produkten ist das der eigentliche Hebel. Man muss nicht mehr hoffen, dass ein Skript oder Agent irgendwie durch die Oberfläche findet. Stattdessen baut man ein System aus benannten, überprüfbaren Szenen.
Warum der testbasierte Ansatz tragfähig wurde
Die Stärke lag nicht einfach darin, dass wir Screenshots per Test erzeugt haben. Tests allein reichen dafür nicht. Tragfähig wurde der Ansatz erst durch drei Eigenschaften, die zusammengekommen sind.
1. Die Ausgabe war strikt an den Katalog gebunden
Ein Screenshot durfte nur dann geschrieben werden, wenn seine ID im Katalog vorhanden und als automatisierbar klassifiziert war. Das verhindert zwei typische Probleme:
- Wildwuchs bei Dateinamen und Ordnern
- verdeckte Drift zwischen Handbuch, Testcode und erzeugten Assets
Damit wurde der Katalog zur maßgeblichen Referenz und die Tests zu ausführbaren Ableitungen daraus.
2. Wir haben Compose-Inhalt statt Betriebssystem-Fenster erfasst
Der zweite wichtige Schritt war, dass wir uns von der Idee verabschiedet haben, immer das vollständige Desktop-Fenster mit nativer Umgebung abbilden zu müssen.
Konkret hieß das bei uns: Wir erfassen den von Compose gerenderten Anwendungsinhalt aus der Desktop-UI-Schicht, statt die Betriebssystem-Hülle um das Fenster herum mitzuschleppen. Gerade weil Invoicer architektonisch sauber in ansteuerbare UI-Zustände zerlegt ist, lassen sich diese Szenen im Test deutlich verlässlicher erzeugen als über äußere Full-Window-Automatisierung.
Für ein Benutzerhandbuch ist meistens nicht die Titelleiste interessant, sondern der fachliche Zustand der Oberfläche:
- Ist der Filter geöffnet?
- Ist der Dialog sichtbar?
- Zeigt die Liste genau die erwarteten Datensätze?
- Ist ein bestimmter Hinweis, Badge oder Workflow-Zustand präsent?
Wenn diese Zustände in Compose kontrollierbar sind, werden sie zu testbaren Szenen. Und testbare Szenen sind sehr viel stabiler als pixelgenaue Betriebssystem-Captures.
3. Die Datenbasis war deterministisch
Automatisierte UI-Screenshots sind nur dann ernsthaft belastbar, wenn die zugrundeliegenden Daten nicht driften. Genau deshalb haben wir einen deterministischen Demo-Datensatz aufgebaut, der über ./gradlew generateDemoDatabase erzeugt wird.
Dieser Generator ist nicht bloß ein kleines Demo-Skript, sondern eine bewusst gestaltete Fixture-Basis:
- feste Zufalls-Seed für reproduzierbare Ergebnisse
- realistische deutsche Stammdaten
- mehrjährige Belegdaten
- Textbausteine, Steuerregeln, Zahlungen, Mahnungen und Exporte
- PDF-bezogene Daten für realistische Vorschau- und Dokumentenszenen
Wichtig dabei: Diese Datenbasis dient nicht nur dem Handbuch. Sie wird auch für Anwendungstests genutzt. Das ist ein großer Unterschied zu vielen Dokumentationsworkflows, in denen Screenshots auf einer separaten, halb-manuellen Demo-Installation entstehen.
Wir haben stattdessen dieselbe Investition doppelt genutzt:
- als reproduzierbares Szenenmaterial für Screenshot-Tests
- als robuste Testfixture für die App selbst
Das reduziert Pflegeaufwand und erhöht den Wert jeder Stunde, die in Testdaten fließt.
Wie schnell sich die Pipeline danach ausbauen ließ
Der eigentliche Aha-Moment kam, als die Infrastruktur stand. Sobald Katalog, Fixture-Loader, Screenshot-Harness und die ersten Kapitelhelfer sauber definiert waren, ließ sich die Suite sehr schnell ausbauen.
Mit diesem Ansatz konnten wir im Verlauf eines Tages eine Screenshot-Test-Suite im Bereich von rund 300 automatisierten Manual-Screenshots aufbauen und die zugehörigen Assets systematisch erzeugen.
Heute liegt der verifizierte Stand bei 336 Screenshot-Tests und 343 automatisierbaren Screenshot-Einträgen. Genau diese Skalierung war mit dem ursprünglichen Full-Window-Denken nicht realistisch.
Die eigentliche Lehre daraus ist für mich schlicht: Der Engpass lag nicht im Screenshot selbst, sondern im fehlenden Modell. Sobald das Modell stimmte, ließ sich die Erzeugung überraschend zügig ausbauen.
Was bewusst außerhalb der Screenshot-Pipeline blieb
Ein weiterer wichtiger Punkt war Disziplin in den Nicht-Zielen.
Nicht jede visuelle Dokumentationsanforderung sollte ein Screenshot-Test werden. Wir haben drei Klassen klar getrennt:
- normale Screenshots aus Compose-Szenen
- Screenshots mit Mocks oder Helper-Scenes für instabile Randfälle
- konzeptionelle Illustrationen mit eigener Generierungspipeline
Diese Trennung war wichtig, weil sie die Pipeline sauber hielt. Wer native Menüs, externe PDF-Viewer und konzeptionelle Diagramme in dasselbe Modell drückt, baut sich schnell unnötige Instabilität ein.
Was sich daraus auch für andere Projekte ableiten lässt
Der Punkt dieses Rückblicks ist nicht nur, dass wir jetzt ein gut bebildertes Benutzerhandbuch haben. Interessanter ist, dass sich das Muster recht gut übertragen lässt.
Wenn du ein Produkt hast, bei dem visuelle Zustände dokumentiert, geprüft oder versioniert werden müssen, lässt sich dieses Muster oft übertragen:
- Behandle visuelle Artefakte als inventarisierte Build-Outputs, nicht als manuelle Nebenprodukte.
- Definiere eine Quelle der Wahrheit für IDs, Zielpfade und inhaltliche Bedeutung.
- Nutze deterministische Testdaten statt improvisierter Demo-Installationen.
- Trenne echte UI-Zustände, Mock-Szenen und Illustrationen bewusst voneinander.
- Erzwinge, dass nur deklarierte Artefakte erzeugt werden dürfen.
Das gilt nicht nur für Benutzerhandbücher. Dasselbe Muster kann auch bei Release-Dokumentation, Onboarding-Material, Audit-Nachweisen, QA-Referenzbildern oder visuellen Regressionssammlungen sinnvoll sein.
Für Webanwendungen würde ich denselben Grundansatz beibehalten, aber mit browsernahen Werkzeugen umsetzen. Playwright ist dafür aus meiner Sicht ein sehr sinnvoller Kandidat. Die Übertragung würde dann typischerweise so aussehen:
- Definiere einen Screenshot-Katalog mit stabilen IDs, Zielpfaden und semantischer Bedeutung.
- Arbeite mit deterministischen Fixtures oder einer gezielt vorbereiteten Testumgebung.
- Steuere die UI mit Playwright über benannte, explizite Zustände statt über lose Klick-Skripte.
- Erfasse gezielt Seitenbereiche oder Komponenten, statt das gesamte Browserfenster zum primären Artefakt zu machen.
- Lass den Build fehlschlagen, wenn erzeugte Assets vom deklarierten Katalog abweichen.
Kurz gesagt: Für moderne Webanwendungen würde ich in vielen Fällen eine Playwright-basierte Variante desselben Grundgedankens empfehlen. Der technische Unterbau ändert sich, aber die eigentliche Lehre bleibt gleich: erst das Inventar der gewünschten Artefakte sauber modellieren, dann die Automatisierung daraus ableiten.
Wo Du das Ergebnis sehen kannst
Das daraus erzeugte Benutzerhandbuch mit den generierten Screenshots findest du hier:
Wichtig ist dabei auch: Der Prozess ist inzwischen reproduzierbar, aber das Ergebnis ist noch nicht perfekt. An einigen Stellen enthalten die Screenshots derzeit noch Fehler oder Unschärfen im fachlichen bzw. visuellen Detail. Diese Stellen werden nach und nach bereinigt, statt wieder in eine manuelle Screenshot-Produktion zurückzufallen.
Zusätzlich zu den 343 automatisierbaren Screenshots gibt es aktuell fünf konzeptionelle Illustrationen. Sie stammen aus einer separaten, SVG-basierten Generierungspipeline und werden als eigene Build-Artefakte in das Handbuch übernommen.
Ein erstes Beispiel für einen automatisch erzeugten Screenshot aus dem Handbuch:
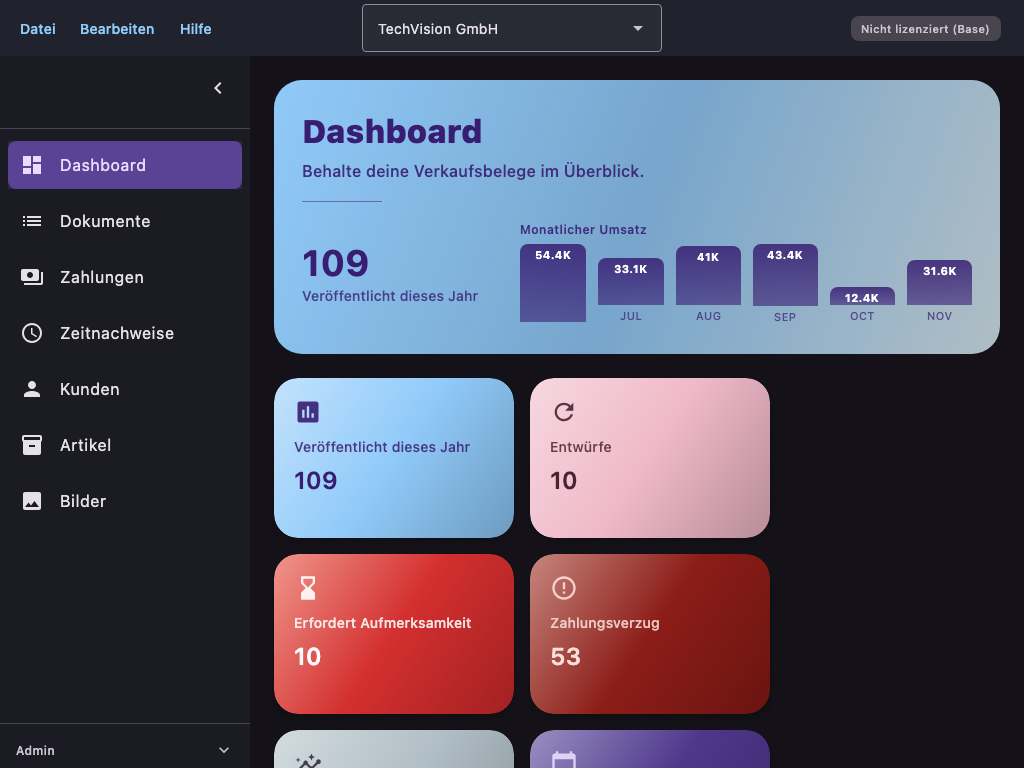
Ein erstes Beispiel für eine zusätzlich generierte konzeptionelle Illustration:

Fazit
Ich halte den Wechsel vom prozessorientierten Fenster-Capture hin zu einem katalog- und testgetriebenen Dokumentationssystem für eine sehr lohnende Engineering-Entscheidung in diesem Bereich.
Der erste Ansatz scheiterte nicht, weil Automatisierung unmöglich gewesen wäre. Er scheiterte, weil er die falsche Abstraktion bevorzugte. Nicht das Fenster war das eigentliche Produkt, sondern das deklarierte Dokumentationsasset.
Sobald wir das verstanden hatten, wurde aus einer diffusen Screenshot-Aufgabe ein reproduzierbarer Pipeline-Baustein.
Und genau darin liegt aus meiner Sicht auch die nützlichste Botschaft für andere Teams: Ja, es ist möglich, hunderte Handbuch-Screenshots systematisch aus Tests zu erzeugen. Entscheidend ist nur, zuerst das richtige Modell zu bauen.
Wenn Du den englischen Input sehen willst, der den Ton solcher Praxisbeiträge beschreibt, findest Du die Prompt-Datei hier.
Wenn Du AGYNAMIX Invoicer praktisch ausprobieren willst, findest Du die Anwendung hier: AGYNAMIX Invoicer.
Hinweis: Dieser Beitrag beschreibt eine Engineering-Retrospektive aus der Entwicklung von AGYNAMIX Invoicer. Die genannten Zahlen entsprechen dem am 2026-03-18 verifizierten Stand im Repository.